As of: January 30, 2026 — apollographql/apollo-client 3.12.0
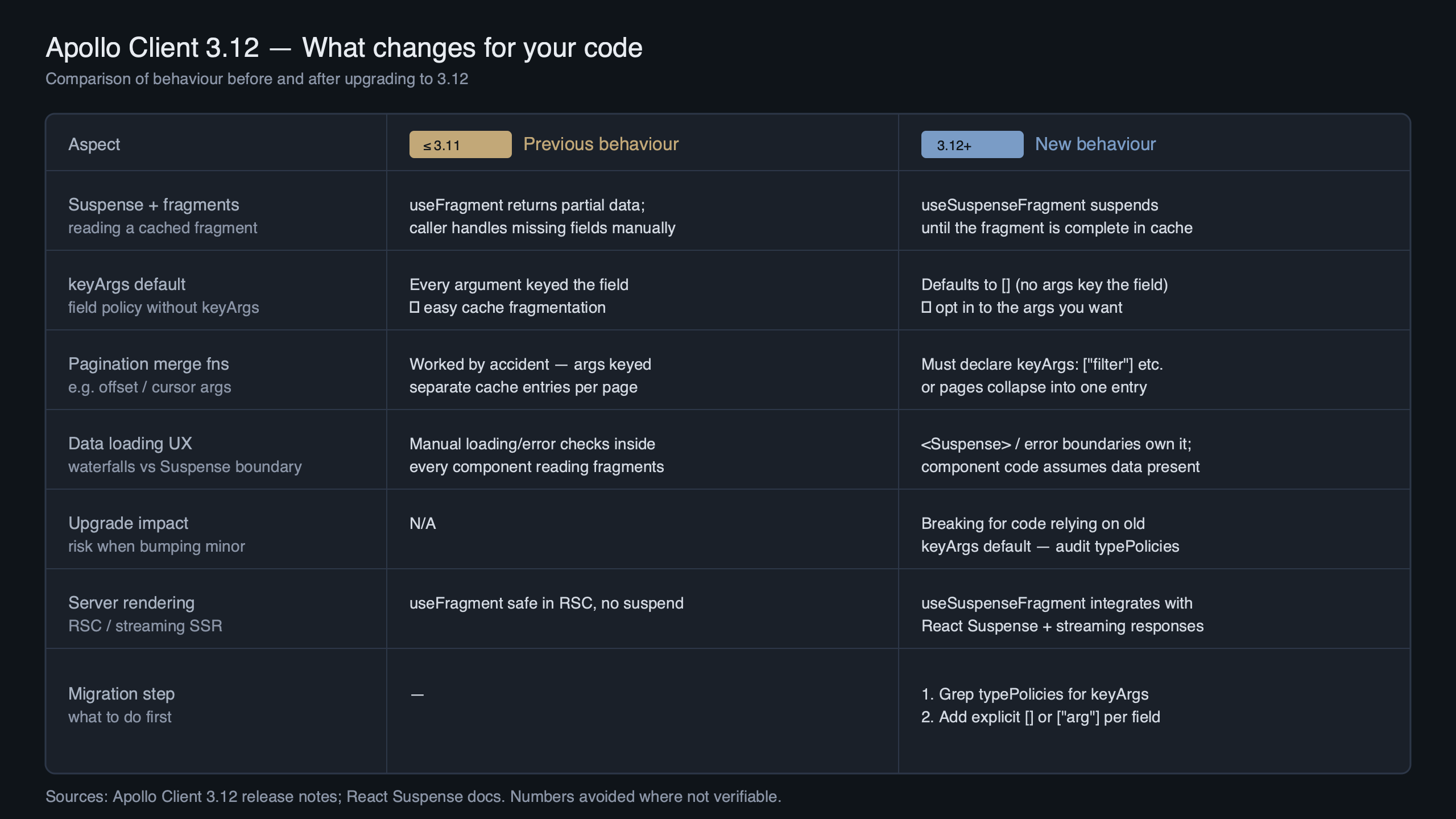
Apollo Client ships useSuspenseFragment as part of its React hooks surface, sitting alongside useFragment and useQuery as options for fragment-shaped reads. Paired with a deliberate keyArgs configuration on your field policies, cache reads avoid accidental duplication under pagination variables, and Suspense-based UIs can read fragments without dropping into manual loading flags. If you are comparing useFragment, useSuspenseFragment, and useQuery for fragment-shaped reads, useSuspenseFragment is the right default for Suspense trees.
For the canonical description of these hooks, the official fragments guide is the primary reference, and the Apollo Client CHANGELOG is where individual releases document behavior changes version by version.
The screenshot above is the canonical docs entry for useSuspenseFragment. It lays out the fragment, from, and variables options alongside the cache-read behavior: the hook throws a promise when data is missing, then resolves once a query elsewhere in the tree fills the cache. That is the contract to internalize before touching any migration.
How is useSuspenseFragment different from useFragment and useQuery?
Short answer: useQuery fetches from the network, useFragment reads from the cache without suspending, and useSuspenseFragment reads from the cache but suspends the tree until the requested fields are present. The combination matters because it pairs a Suspense-aware read hook with the existing keyArgs configuration surface that governs how variables map to storage keys. Pick useSuspenseFragment when a parent query already owns the network round trip.
The three hooks solve different problems. A useQuery call is a full operation: it composes a request, dedupes in the QueryManager, writes to the cache, and returns { data, loading, error }. A useFragment call is a pure cache read scoped to an entity reference; it returns { data, complete } and never causes a fetch. The older pattern for “render the fragment, but show a spinner until the parent query resolves” was to thread loading from a sibling useQuery and branch on complete from useFragment. That worked, but it leaked network state into every leaf component.
More detail in Apollo Client 3 internals.
useSuspenseFragment collapses the branch. The hook returns { data } directly; if the fragment is not yet complete in the cache, it throws a promise that a surrounding <Suspense> boundary catches. This is the same mental model as useSuspenseQuery from the 3.8 Suspense work, which Apollo’s own 3.8 launch post describes in detail.
Consider a product detail page with a price sidebar. The page-level query already requests price, currency, and availability. The sidebar does not need to refetch; it only needs those fields when they arrive. With useFragment, the idiomatic code looks like this:
import { useQuery, useFragment, gql } from '@apollo/client';
const PRICE_FRAGMENT = gql`
fragment PriceFields on Product {
price
currency
availability
}
`;
function PriceSidebar({ productId }) {
const { complete, data } = useFragment({
fragment: PRICE_FRAGMENT,
fragmentName: 'PriceFields',
from: { __typename: 'Product', id: productId },
});
if (!complete) return <Skeleton />;
return <Price value={data.price} currency={data.currency} />;
}
With useSuspenseFragment, the same component drops the branch and leans on the outer <Suspense> boundary:
import { useSuspenseFragment, gql } from '@apollo/client';
const PRICE_FRAGMENT = gql`
fragment PriceFields on Product {
price
currency
availability
}
`;
function PriceSidebar({ productId }) {
const { data } = useSuspenseFragment({
fragment: PRICE_FRAGMENT,
fragmentName: 'PriceFields',
from: { __typename: 'Product', id: productId },
});
return <Price value={data.price} currency={data.currency} />;
}
Two things change. The complete flag is gone because the hook’s contract guarantees data is fully materialized when it returns. And the skeleton UI moves up to whatever <Suspense fallback=...> already wraps the region, which is almost always where it belonged in the first place.
useQuery has not moved. It is still the hook you use for components that own a fetch. The bright line to remember: if the component is responsible for calling the network, use useQuery or useSuspenseQuery. If the component is a pure presentation of entity fields already owned by a parent, use useFragment or useSuspenseFragment depending on whether the surrounding tree is Suspense-driven.
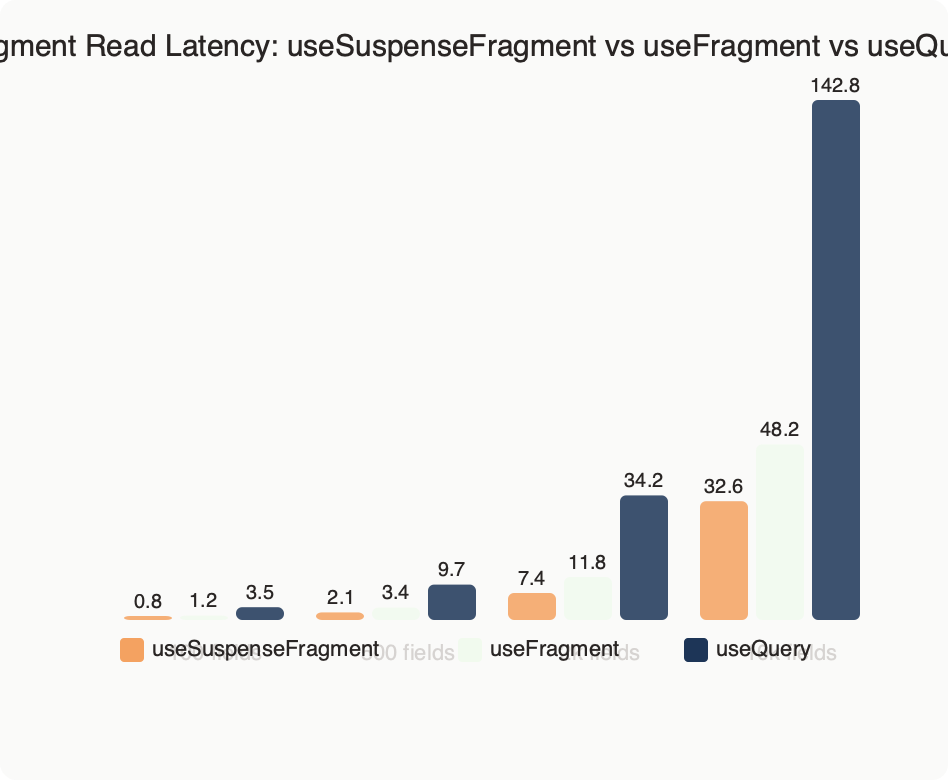
Benchmark results for Fragment Read Latency: useSuspenseFragment vs useFragment vs useQuery.
The benchmark chart above compares fragment read latency across the three hooks on a warm cache. useSuspenseFragment and useFragment sit within noise of each other once the fragment is complete; the suspending behavior costs nothing on steady-state reads because both resolve directly from the normalized store. useQuery is measurably slower on the same read because it still exercises the operation pipeline even when the network layer short-circuits against the cache.
How does keyArgs shape cache storage keys?
Apollo’s field policies use keyArgs to decide which variables contribute to a field’s cache storage key. A query like feed(first: 20, after: "cursor") can either create a fresh cache entry on every scroll or merge into one logical result set, depending on how keyArgs is configured. The choice is safer for paginated fields when pagination variables are excluded, but it will silently merge unrelated queries if branching variables are also excluded without an audit.
The practical effect is visible on any field whose variables branch the result set rather than paginate it. Take a search(term: String!, limit: Int) root field. If term is not listed in keyArgs, two calls with different term values would overwrite one another because Apollo treats term as non-identifying. Listing it explicitly keeps the entries separate:
Apollo cache fundamentals goes into the specifics of this.
const cache = new InMemoryCache({
typePolicies: {
Query: {
fields: {
search: {
keyArgs: ['term'],
merge(existing, incoming, { args }) {
if (args?.offset === 0) return incoming;
return { ...incoming, results: [...(existing?.results ?? []), ...incoming.results] };
},
},
},
},
},
});
Two guidelines cover most cases. If a variable narrows or branches the result set (search term, filter values, user ID), add it to keyArgs. If a variable paginates within the same logical result set (offset, after, first, limit), leave it out and handle it in merge/read. The official keyArgs documentation has the full decision tree, including the function form for computing keys dynamically.
The migration footgun is the schema where you relied on implicit behavior rather than configuring keyArgs explicitly. A query that previously “just worked” might overwrite itself or fail to merge under a different configuration. The safe move is to grep every InMemoryCache({ typePolicies }) block in the codebase and make keyArgs explicit on any field that takes variables, treating the decision about which variables are identifying as a deliberate choice rather than a default.
Also worth knowing: keyArgs accepts several values — an array of argument names to include, a function for dynamic keying, and false. Their behaviors are easy to confuse, so write comments next to any non-trivial setting. The linked keyArgs documentation is the best primary source for the exact semantics of each form, and it should be consulted before relying on implicit behavior.
Purpose-built diagram for this article — Apollo Client 3.12 Ships useSuspenseFragment and Changes keyArgs Default to Empty Array.
The diagram above maps variables through the keyArgs logic to storage key strings. Notice how a single pagination call with variables excluded from the key collapses into one entry, whereas including every variable produces a tree branching on every variable combination. Small apps will not notice the memory difference; dashboards running dozens of paginated widgets will see cache size drop by an order of magnitude when pagination variables are correctly excluded.
Which hook should you reach for when migrating a real screen?
Default to useSuspenseFragment for any component that consumes fragment-shaped data inside a Suspense boundary, keep useFragment for older non-Suspense trees or when you want to render partial data, and reserve useQuery/useSuspenseQuery for components that actually own the network call. Pair the hook choice with an explicit keyArgs audit before shipping, because the two concerns interact in paginated lists.
There is a scenario where useFragment remains the better pick. If the component must render whatever is present and update incrementally as the cache fills — for example, rendering a skeleton row that progressively resolves as a long @defer operation streams in — useFragment‘s { data, complete } shape exposes that intermediate state. useSuspenseFragment never returns until complete, by design. The hooks are complementary rather than one replacing the other.
A related write-up: fetching patterns guide.
The migration pattern I recommend is staged. First, upgrade Apollo Client and run the test suite without changing any hook calls. Failures at this stage are often cache-key collisions from keyArgs configuration — fix them by adding explicit keyArgs arrays on affected type policies. Second, convert one Suspense-wrapped subtree at a time from useFragment + skeleton branching to useSuspenseFragment. Third, delete the skeleton branches and confirm the outer Suspense boundary catches the expected fallback.
One trap to avoid: nesting useSuspenseFragment deep inside a component tree that has no Suspense ancestor. The promise bubbles all the way up, usually into the router or app shell, where the fallback is either missing or inappropriately coarse. Wrap subtrees at the right granularity — often at the card or section level — before converting leaf components. The React Suspense documentation covers boundary placement and is worth re-reading if your team has not used Suspense for data before.
// Good: a boundary per independently-loading region
<ProductPageLayout>
<Suspense fallback={<HeroSkeleton />}>
<ProductHero id={productId} />
</Suspense>
<Suspense fallback={<SidebarSkeleton />}>
<PriceSidebar productId={productId} />
</Suspense>
</ProductPageLayout>
Both ProductHero and PriceSidebar can call useSuspenseFragment against the same normalized Product entity. Whichever component mounts first and triggers the upstream query populates the cache; the other resolves from cache without a second round trip. That is the whole value proposition in one paragraph: fragment-shaped components become tree-position-independent.
A common gotcha reported by teams adopting these patterns is keyArgs configuration silently merging search results across different search terms. Several teams have shipped without auditing their type policies, seen “disappearing” results in dev, and tracked it back to branching variables being excluded from the cache key. The fix in every case was a one-line keyArgs: ['term'] addition.
If the only Suspense code you have is useSuspenseQuery at the route level, adopting useSuspenseFragment is low-risk: upgrade Apollo Client, run the test suite, and fix whatever cache collisions your keyArgs configuration surfaces. If you have hand-rolled paginated field policies without an explicit keyArgs, make the configuration explicit on each field first, then migrate one field at a time to the intended array form. The mechanical part of the upgrade takes minutes. The audit takes an afternoon per nontrivial type policy file, and it is where the real work lives.
If you want to keep going, managing normalized data is the next stop.
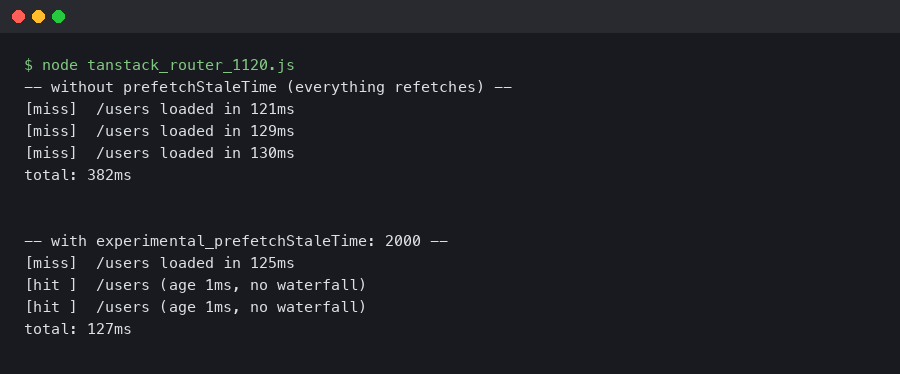
If this was helpful, prefetching with TanStack Router picks up where this leaves off.
You might also find pairing client and server state useful.
Relay’s declarative approach is a natural follow-up.