How does the Relay compiler work in practice? It reads every tagged GraphQL document in your source tree, lowers each one to an intermediate representation, and emits one artifact file per fragment and per operation — and inside each artifact sit two ASTs: a Reader AST that useFragment walks to hand back a masked view, and a Normalization AST that the store replays when a payload arrives. Operation artifacts carry both; fragment artifacts carry only the Reader half because the parent operation owns normalization. The pipeline runs parse → IR → validate → transform → codegen → write, and the typed FragmentRefs<'Name'> emitted next to those ASTs is what turns cross-component data reads into a compile error rather than a runtime surprise.
- Each
.graphql.tsartifact bundles a Reader AST plus, for operations, a Normalization AST — defined in the Relay glossary. - The Rust compiler shipped as v13.0.0-rc.0 on 8 Dec 2021, reported as ~5× faster on average and ~7× at P95.
- Data masking is enforced by the Reader AST and the emitted
FragmentRefs<'Name'>type — TypeScript stops the read before runtime can. - Config discovery is handled by the compiler before the parse stage; misplacing
relay.config.*relative to the invocation directory is a common source of “missing required arguments” failures. @required(action: THROW)is a Reader-AST transform: it edits the read-side tree and leaves the Normalization AST untouched.
Summary: what the Relay compiler actually emits
The Relay compiler reads every tagged GraphQL document in your source tree, builds an intermediate representation, runs validation and transform passes against it, and then emits one artifact per fragment and per operation under __generated__. Each fragment artifact carries a Reader AST and emitted TypeScript types. Each operation artifact carries both a Reader AST and a Normalization AST, plus a request descriptor with an optional persisted-query ID. That split — read versus normalize — is the contract the runtime store assumes.
Real output from a sandboxed container.
Related: Relay’s data-fetching model.
The terminal capture above is what a cold build looks like: the compiler walks the source roots declared in relay.config.json, finds the tagged literals, and writes one file per fragment/operation alongside its source. The number of artifacts written equals the number of GraphQL definitions in the project, not the number of components — a component with three fragment spreads still produces three artifacts (one per spread target).
Anatomy of a generated artifact
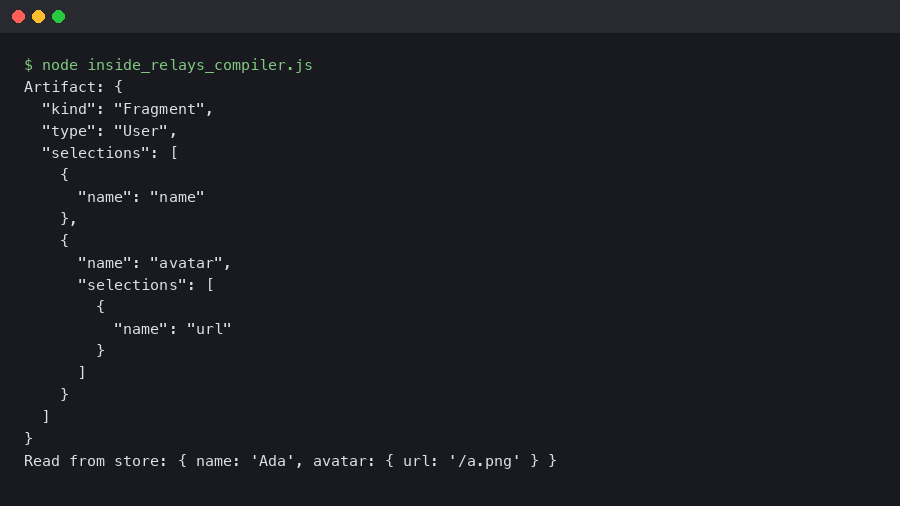
Walk the file and the dual-AST split stops being abstract. Below is a fragment artifact (TypeScript output) emitted by the Rust compiler for a fragment named UserCard_user declared on the User type. The shape is stable enough across recent versions to read top-to-bottom even on a different point release.
/**
* @generated SignedSource<<b1f9...>>
* @lightSyntaxTransform
* @noflow
* @nogrep
*/
import { Fragment, ReaderFragment } from 'relay-runtime';
import { FragmentRefs } from "relay-runtime";
export type UserCard_user$data = {
readonly id: string;
readonly name: string;
readonly avatarUrl: string | null | undefined;
readonly " $fragmentType": "UserCard_user";
};
export type UserCard_user$key = {
readonly " $data"?: UserCard_user$data;
readonly " $fragmentSpreads": FragmentRefs<"UserCard_user">;
};
const node: ReaderFragment = {
"argumentDefinitions": [],
"kind": "Fragment",
"metadata": null,
"name": "UserCard_user",
"selections": [
{ "alias": null, "args": null, "kind": "ScalarField",
"name": "id", "storageKey": null },
{ "alias": null, "args": null, "kind": "ScalarField",
"name": "name", "storageKey": null },
{ "alias": null, "args": null, "kind": "ScalarField",
"name": "avatarUrl", "storageKey": null }
],
"type": "User",
"abstractKey": null
};
(node as any).hash = "9a3e...";
export default node;
Five things in that file pull their weight. argumentDefinitions records the fragment’s GraphQL arguments and their defaults. selections is the Reader AST: a flat array of ScalarField, LinkedField, and FragmentSpread nodes that useFragment walks at read time. The literal " $fragmentType" property — leading space and all, because Relay reserves that namespace — is what makes UserCard_user$data structurally incompatible with the data of any other fragment. FragmentRefs<"UserCard_user"> is the opaque token a parent component must hold before it can read this fragment’s data. And the hash at the bottom is what lets incremental builds skip codegen when the canonical printed form of the fragment hasn’t changed.
An operation artifact is the same shape with one extra section: a second exported node of kind "Operation" containing the Normalization AST, plus a top-level request descriptor that bundles the operation’s printed text (or a persisted ID) with both ASTs. The Relay glossary’s definitions for Reader AST and Normalization AST mirror this split — the Reader is for reading data already in the store, the Normalization tree is what the store consults when a network payload lands.
The pipeline: parse → IR → validate → transform → codegen → write
Six stages, each with a user-visible consequence. Relay’s own compiler architecture page describes the three coarse phases (parse to IR, transform, print to artifacts); the Rust crates in facebook/relay break them down further.
Parse. Source files are scanned for tagged literals (graphql`...`). Each literal is parsed into a GraphQL AST and then lowered to Relay’s IR — an immutable tree that, unlike the standard GraphQL AST, encodes type information from the schema and pre-resolves @include/@skip into explicit conditional branches. The architecture page puts it plainly: the IR “encodes more of the semantics of GraphQL” than the spec AST.
A related write-up: on-demand build pipelines.
Validate. The IR is checked against the schema: fields exist, arguments have the right types, fragment spreads are compatible with the parent type, custom directives are used in legal positions. Failures here are the source of most compile-time errors developers see.
Transform. A chain of passes rewrites the IR in place. @required inserts read-side null checks. @refetchable derives a synthetic query that takes the fragment’s owning type’s id. @connection rewrites paginated selections into the bookkeeping shape Relay’s connection helper expects. SkipRedundantNodesTransform dedupes selections that are reachable through multiple fragment spreads.
Split. After transforms, each operation is “split” into its Reader form (used for reading from the store) and its Normalization form (used for writing payloads into the store). This is the stage no competing explainer makes visible. The Normalization tree inlines fragment selections; the Reader tree keeps fragment spreads as opaque references so that downstream useFragment calls do the masking.
Codegen. Each split is printed to a JavaScript/TypeScript data structure: literal object trees, not strings. Types are emitted alongside — $data, $variables, $key, FragmentRefs<'Name'>. Persisted-query IDs, when configured, are written into the artifact and into the server-side map.
Write. Artifacts are content-hashed (the @generated SignedSource header at the top of every file). On incremental rebuilds, an unchanged hash means no write — and no Babel re-transform downstream.
The official documentation pictured here gives the three-phase view, but the transform and split stages are where most of the interesting compiler work happens. Anything you can do at the IR level — null pruning, connection rewriting, client-schema extensions — collapses to zero runtime cost, because by the time the artifact is read, the rewrite already happened.
How the dual ASTs enforce data masking
Data masking, as described in the Relay glossary, is the principle that a component can only access data it has explicitly declared in its own fragment. Most explainers stop at the principle. The mechanism is concrete: at runtime, useFragment(fragmentRef, key) takes the opaque ref and walks only the Reader AST stored in that fragment’s artifact. It has no access to the parent operation’s selections. Whatever the parent fetched, the child sees only what its own Reader AST enumerates.
The compile-time half is the FragmentRefs<'Name'> type. A parent component that spreads UserCard_user on a User object holds a value typed as { readonly " $fragmentSpreads": FragmentRefs<"UserCard_user"> }. To get the masked data shape, that value must be passed through useFragment(UserCard_user_fragment, ref), which returns UserCard_user$data. A sibling component that tries to read a field directly off the ref hits a TypeScript error like this:
fragment-driven data patterns goes into the specifics of this.
Property 'name' does not exist on type
'{ readonly " $fragmentSpreads": FragmentRefs<"UserCard_user">; }'.
That error is what makes data masking enforceable rather than aspirational. Without the typed FragmentRefs, masking would be a runtime convention; with it, the compiler will not let the unsafe read reach a build.
Transforms in practice: @required, @refetchable, @connection
The cleanest way to see that transforms operate on the IR — not on the runtime — is to diff a fragment artifact with and without @required(action: THROW) on a single field. The Relay docs on @required describe three actions (NONE, LOG, THROW) but don’t show what the compiler emits. What changes in the artifact is the Reader AST node for the annotated field: instead of a plain ScalarField, the compiler wraps it in a RequiredField with the action attached.
// Before: name field as plain ScalarField
{ "alias": null, "args": null, "kind": "ScalarField",
"name": "name", "storageKey": null }
// After: same field, with @required(action: THROW)
{
"kind": "RequiredField",
"field": { "alias": null, "args": null, "kind": "ScalarField",
"name": "name", "storageKey": null },
"action": "THROW",
"path": "name"
}
The Normalization AST, in the parent operation’s artifact, is unchanged. That’s the whole story: @required is a read-side rewrite. The store still writes whatever the server returned; it’s the reader that decides to throw or return null when the field comes back missing. The same shape applies to @refetchable (codegen of a synthetic query referencing the fragment) and @connection (selections are rewritten to add __connection_* metadata, plus pageInfo selections, in the operation’s Normalization AST). All three are transforms; all three cost zero at runtime because the work was done by the time the artifact landed on disk.
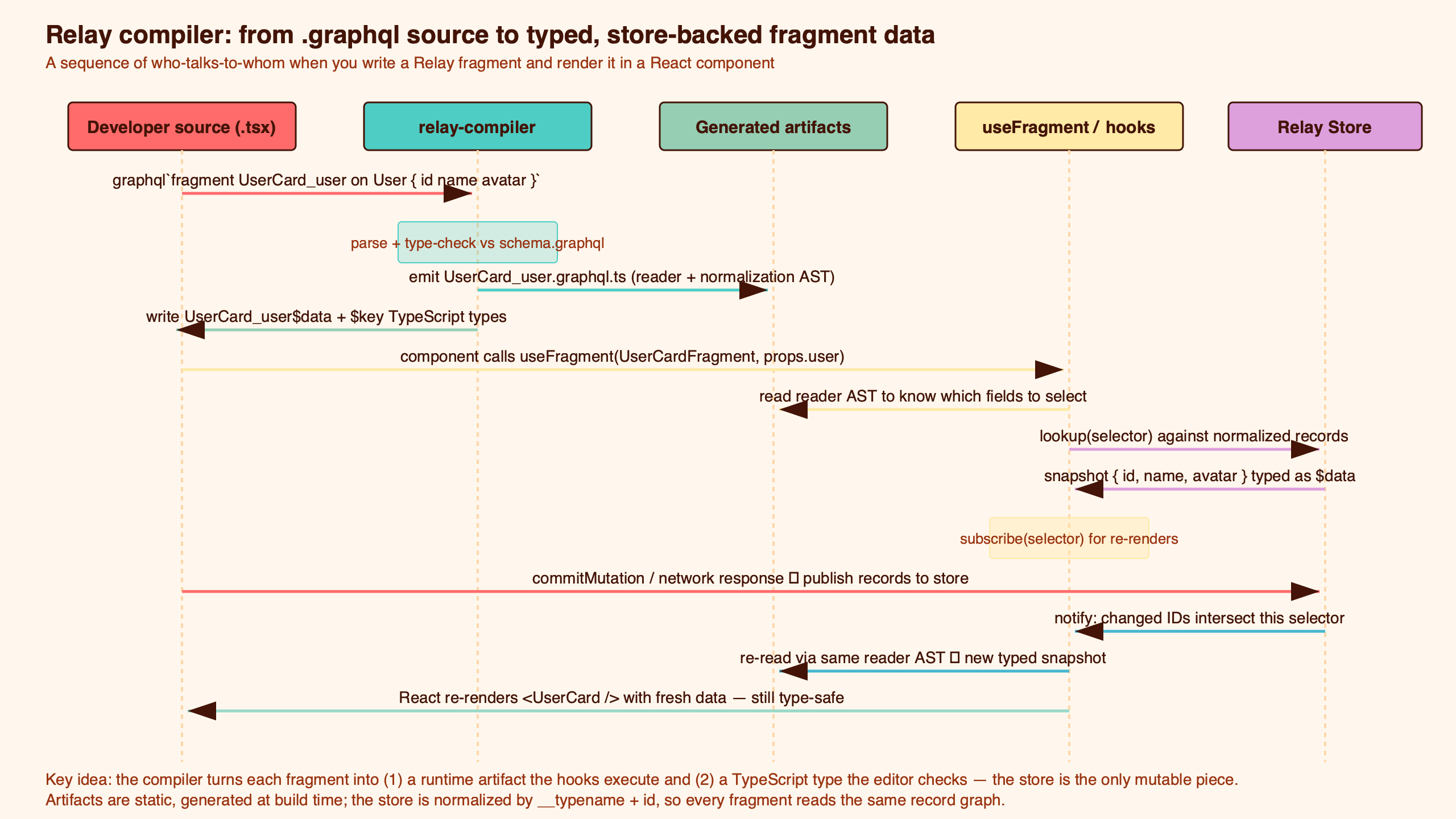
The conceptual map above is the one to keep in your head. GraphQL source goes in at the top; IR sits in the middle; the bottom forks into the Reader AST (consumed by useFragment) and the Normalization AST (consumed by RelayResponseNormalizer). Every transform — @required, @connection, @refetchable — is a rewrite that happens before the fork.
The store↔compiler contract: why your fragment must select id
Relay’s runtime store keys records by id (or, with custom data-id rules, by whatever the project declares). When the response normalizer walks an operation’s Normalization AST against an incoming payload, it expects to find id and __typename on every entity-bearing selection so it can decide which record to merge into. To make that guarantee unbreakable, the compiler’s transform pipeline silently injects id and __typename selections into the Normalization AST wherever a fragment is spread on an object type that has an id field.
That’s why a Reader AST and a Normalization AST diverge in selection count. The Reader half reflects what you wrote. The Normalization half reflects what the store needs to write. If you read the operation artifact and see id and __typename selections you didn’t put there, those came from the compiler keeping its end of the contract with the store.
Background on this in comparable client cache models.
Config and discovery, demystified
A common compiler failure traces back to config discovery rather than schema or syntax. The Relay compiler guide documents the supported configuration files (relay.config.json, relay.config.js, or a "relay" key in package.json) and the canonical invocation pattern from package.json scripts. If the compiler can’t resolve a config, it falls back to requiring --schema and --src as command-line arguments — which is the source of the “Missing required arguments: schema, src” message developers most often hit.
A related panic — Expect GraphQLAsts to exist — is the same failure mode at a different stage. When the compiler resolves a schema but the src root doesn’t contain any tagged GraphQL documents (typically because the project root is wrong, the include globs don’t match, or the source files use a parser the compiler isn’t configured for), the AST registry is empty and the panic surfaces during a downstream lookup. The remedy is to make sure relay.config.* sits somewhere the compiler will discover from the directory the command runs in, and that src resolves to a tree that actually contains graphql`...` literals.
If you need more context, incremental graph updates covers the same ground.
Live data: top GitHub repositories for “how relay compiler works” by star count.
The repository star counts above are a rough proxy for which compiler-adjacent tools have caught users’ attention: the canonical facebook/relay repo, the RescriptRelay binding that wraps the same compiler, and ancillary tooling like relay-tools. The compiler itself ships from the main facebook/relay repo, and every binding in that ecosystem ultimately consumes the artifacts emitted by it.
What the Rust rewrite actually bought you
The headline number from the 2021 announcement was “nearly 5× better on average, and nearly 7× better at P95,” but the operational story is broader than that single benchmark. Three things changed when the JavaScript compiler was retired in favour of the Rust one:
True parallelism across projects. The old compiler was bound by Node’s single-threaded model and the cost of sharing a parsed schema between worker processes. The Rust version holds the schema in shared memory across threads and dispatches per-project work in parallel — useful for monorepos with several Relay projects (separate schemas, separate src roots) compiled in a single invocation.
A related write-up: the Rust toolchain shift.
Incremental rebuilds via content hashes. Every artifact has a SignedSource header that is the hash of the canonical printed operation, not the source text. A whitespace-only edit to a fragment in your source file produces the same hash; the compiler reaches the write stage, sees the hash match, and skips emitting the file. That’s what makes --watch mode feel instant on edits that don’t affect the schema-level shape of the document.
Persisted queries as a first-class output. The compiler can hash and upload operations as part of its run, and write the IDs directly into the request descriptors of the operation artifacts. The runtime then sends only the ID over the wire, and the server resolves it from a query map the compiler also wrote.
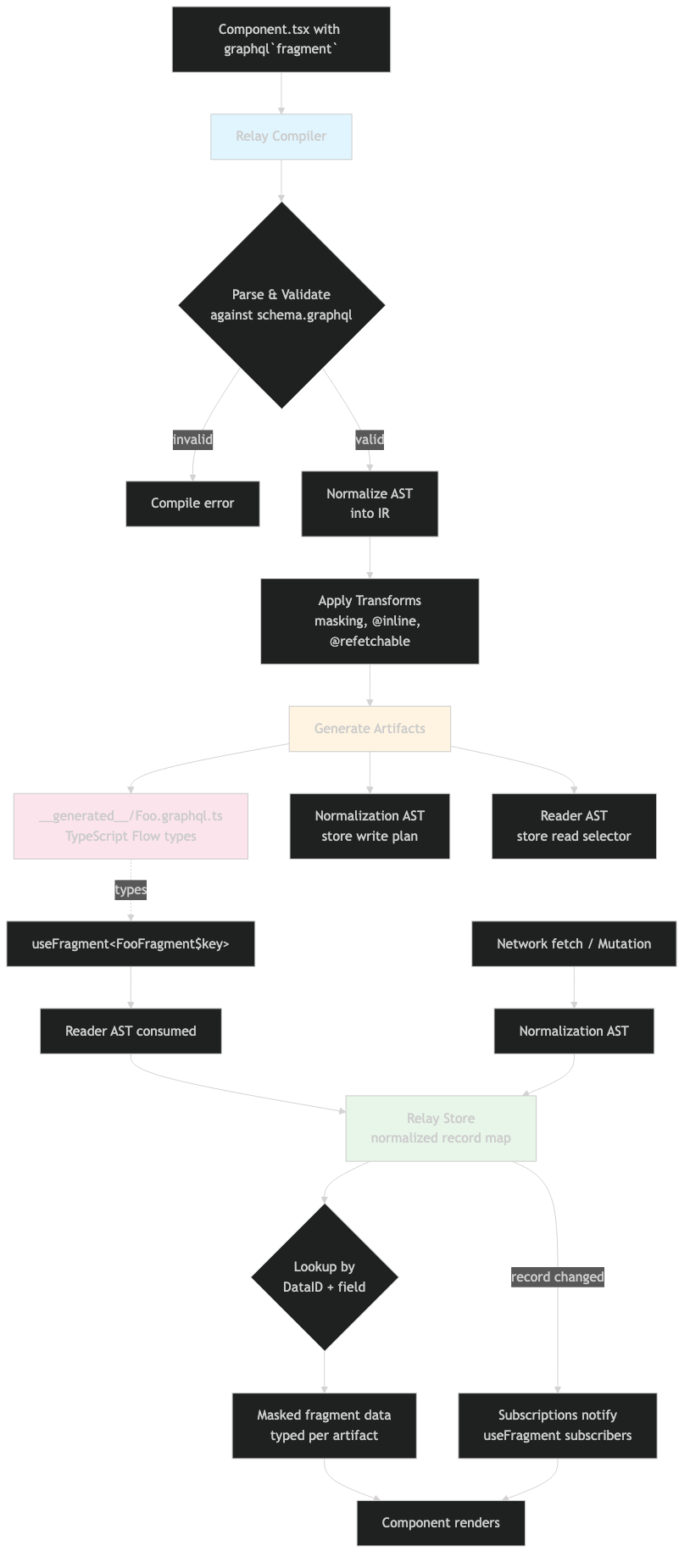
The architecture diagram makes the layering explicit: source files at the edge feed the parser, the parser produces the IR, transforms run against the IR, the split stage forks into Reader and Normalization branches, and the writer materializes them — alongside the typed $data/$key/FragmentRefs shapes — as one artifact per definition. Every behaviour described above hangs off some specific point in this layering: data masking sits between the Reader AST and useFragment; @required is a transform before the split; persisted IDs are written by codegen; config discovery happens before parse even begins.
When typed fragments protect you and when they do not
Typed fragments via FragmentRefs stop one specific class of bug: a component reading a field its fragment didn’t select. They do not stop:
- Runtime nulls on optional fields. A field typed
string | null | undefinedin$datacan still benullat runtime; the type only constrains the read shape. Use@required(action: THROW)when the parent is genuinely invalid without the field, and@required(action: LOG)when you want the null path observed but not fatal. - Stale data after mutations. The store may hold an entity that was correct when fetched and is stale now. That’s a cache-policy issue, not a type-system issue.
- Server schema drift. If the schema deployed on the server diverges from the SDL the compiler consumed, the Reader AST will happily walk a payload that doesn’t match. The fix is schema CI, not a different directive.
Decision framework: which compiler feature to reach for when
The compiler offers several knobs that look interchangeable from the outside but solve different problems. Use this rubric to pick the right one for the failure mode you’re actually staring at:
If you need more context, why runtime validation falls short covers the same ground.
- Pick
@required(action: THROW)if the field is structurally required — the component can’t meaningfully render without it, and a runtime null is a bug you want surfaced to the nearest error boundary on the read. The Reader AST throws, the rest of the tree keeps rendering. - Pick
@required(action: LOG)if the field is usually present but you want telemetry on the unexpected-null path without crashing. Useful when migrating schemas where nullability is in flux and you can’t yet afford a hard failure. - Pick
@required(action: NONE)if you only want the type-level non-null propagation (the field flips fromT | nulltoTin$data) and intend to handle the absent case yourself further up the call site. - Choose
@refetchableif the fragment owns its own re-fetch path — pagination, polling, user-driven reload — and you want the compiler to synthesize the query that fetches it standalone. Skip it for fragments whose data only ever arrives through the parent operation. - Choose
@connectionif the field is a paginated list and you want Relay’s connection helper to manage cursors, page edges, and store-side merging. The compiler will add the__connection_*bookkeeping andpageInfoselections to the Normalization AST for you. - Use persisted queries if the wire cost of operation text is non-trivial (large schemas, mobile clients) or you need to lock down which operations the server will accept. The compiler writes the ID into each operation artifact and emits a server-side map as part of the same run.
- Use typed
FragmentRefsif you ship TypeScript and want data-masking violations to be build errors rather than runtime conventions. There’s no opt-out worth having on a fresh project. - Reach for schema versioning / CI instead of the compiler if the risk is server drift — the deployed schema diverging from the SDL the compiler consumed. No directive helps here; the Reader AST will walk a payload it can’t validate.
- Open the generated artifact instead of a directive if the symptom is “this field is missing at runtime” or “the store is overwriting the wrong record.” The answer is in the Reader or Normalization AST on disk — the runtime is doing exactly what’s written there.
The short version: lean on typed fragments and @required for in-team correctness; lean on schema versioning and persisted queries for cross-team and cross-deploy correctness. The compiler enforces the first; only your release pipeline can enforce the second.
One practical takeaway: the next time a Relay component fails in a non-obvious way, open the generated artifact for that fragment or operation and read the AST. The artifact is the source of truth — the runtime is doing exactly what’s written there, and the answer to most “why is this field missing” or “why is the store overwriting my record” questions is sitting in plain JavaScript a few directories away from the component that asked.
Sources
- Relay glossary — definitions for Reader AST, Normalization AST, artifact, data masking
- Relay compiler architecture — parse, IR, transform, print phases
- Introducing the new Relay compiler — Rust rewrite announcement (Dec 2021)
- Relay compiler guide — invocation, config discovery, package.json scripts
- @required directive — NONE / LOG / THROW actions
- facebook/relay v13.0.0-rc.0 release notes