In the rapidly evolving world of web development, managing server state in React applications remains a central challenge. For years, developers relied on a combination of useEffect, component state, and global state managers like Redux to handle data fetching, caching, and synchronization. While functional, this approach often leads to boilerplate code, race conditions, and complex logic for handling caching, re-fetching, and error states. This is where the latest developments in libraries like React Query (now part of the TanStack Query family) are making significant waves. The latest React Query News isn’t just about a library; it’s about a paradigm shift in how we think about data in our applications.
React Query positions itself not merely as a data-fetching library but as a comprehensive server-state management solution. It provides a declarative, hook-based API that automates the complexities of interacting with asynchronous data. But a truly performant application doesn’t stop at the frontend. The snappiest UI, powered by React Query, is only as fast as the backend that serves it. This article dives deep into the modern capabilities of React Query, demonstrating how its powerful frontend patterns are intrinsically linked to backend database efficiency, complete with practical SQL examples to illustrate the full picture.
The Core of React Query: From Imperative Fetching to Declarative State
The fundamental problem React Query solves is abstracting away the imperative process of fetching data and replacing it with a declarative way of describing what data your component needs. This shift simplifies component logic and eliminates a whole class of common bugs.
From useEffect Chaos to useQuery Clarity
Traditionally, fetching data in a React component involved the useEffect hook. This approach forces the developer to manually manage loading states, error states, and the fetched data itself. It also doesn’t provide any out-of-the-box mechanism for caching or re-fetching data when it becomes stale.
React Query introduces the useQuery hook, which elegantly handles these concerns. You provide it with a unique queryKey to identify the data and a queryFn that returns a promise (typically an API call), and it returns all the state you need: data, isLoading, isError, isSuccess, and more.
import { useQuery } from '@tanstack/react-query';
import axios from 'axios';
const fetchArticles = async () => {
const { data } = await axios.get('/api/articles');
return data;
};
function ArticleList() {
const { data, isLoading, isError, error } = useQuery({
queryKey: ['articles'],
queryFn: fetchArticles,
});
if (isLoading) {
return <span>Loading articles...</span>;
}
if (isError) {
return <span>Error: {error.message}</span>;
}
return (
<ul>
{data.map((article) => (
<li key={article.id}>{article.title}</li>
))}
</ul>
);
}The Backend Connection: The SQL Behind the Fetch
The queryFn in the example above calls an API endpoint, /api/articles. On the server, this endpoint executes a database query to retrieve the data. The performance of this SQL query directly impacts the user’s perceived loading time. A slow database query will make even the most optimized frontend feel sluggish. Here’s what the backend schema and query might look like.
-- Table Schema for 'articles'
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title VARCHAR(255) NOT NULL,
content TEXT,
author_id INT,
created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
published_at TIMESTAMP WITH TIME ZONE,
comment_count INT DEFAULT 0,
FOREIGN KEY (author_id) REFERENCES users(id)
);
-- The SQL query executed by the /api/articles endpoint
SELECT id, title, author_id, created_at
FROM articles
WHERE published_at IS NOT NULL
ORDER BY created_at DESC
LIMIT 20;Understanding this connection is crucial. Optimizing this SQL query—for instance, by adding an index—is as important as managing state effectively on the frontend with React Query.
Implementing Mutations: Syncing Frontend Actions with Backend Integrity
Reading data is only half the story. Applications need to create, update, and delete data. React Query provides the useMutation hook for these side effects, offering powerful features like optimistic updates and seamless query invalidation to keep the UI in sync with the backend.
Optimistic Updates with useMutation
When a user performs an action, like posting a comment, they expect immediate feedback. Waiting for the server to confirm the action before updating the UI can feel slow. useMutation allows you to implement “optimistic updates,” where the UI is updated instantly, assuming the server request will succeed. If it fails, React Query automatically rolls back the change. A key part of this flow is invalidating stale data. After a successful mutation, you can use the queryClient to invalidate the queries related to the data that changed, triggering an automatic, background re-fetch.
import { useMutation, useQueryClient } from '@tanstack/react-query';
import axios from 'axios';
const postComment = async (newComment) => {
// newComment = { articleId: 1, text: "Great article!" }
const { data } = await axios.post(`/api/articles/${newComment.articleId}/comments`, newComment);
return data;
};
function CommentForm({ articleId }) {
const queryClient = useQueryClient();
const mutation = useMutation({
mutationFn: postComment,
onSuccess: () => {
// Invalidate and refetch the comments for this article
queryClient.invalidateQueries({ queryKey: ['comments', articleId] });
// Also invalidate the article itself to update the comment count
queryClient.invalidateQueries({ queryKey: ['articles', articleId] });
},
});
const handleSubmit = (event) => {
event.preventDefault();
const text = event.target.elements.commentText.value;
mutation.mutate({ articleId, text });
};
// ... form JSX
}Ensuring Atomicity with SQL Transactions
The mutation above triggers two potential changes on the backend: a new comment is inserted, and the comment_count on the `articles` table should be incremented. These two operations must happen together or not at all to prevent data inconsistency. This is a perfect use case for a SQL transaction. A transaction wraps multiple SQL statements into a single, atomic unit of work.
-- SQL Transaction for posting a new comment
BEGIN;
-- Insert the new comment into the comments table
INSERT INTO comments (article_id, user_id, content)
VALUES (1, 123, 'This is a great point!');
-- Update the comment_count on the corresponding article
UPDATE articles
SET comment_count = comment_count + 1
WHERE id = 1;
-- Commit the transaction to make the changes permanent
COMMIT;
-- If any statement fails, the entire transaction can be rolled back
-- ROLLBACK;This backend guarantee of data integrity is the foundation upon which the optimistic UI updates of React Query are built. This synergy is a cornerstone of modern full-stack development, whether you’re building with Next.js News, Remix News, or in the React Native News ecosystem with tools like Expo.
Advanced Techniques for a World-Class User Experience
Beyond the basics, React Query offers a suite of advanced features that, when combined with backend best practices, can dramatically improve application performance and user experience.
Fine-Tuning Caching and Re-fetching
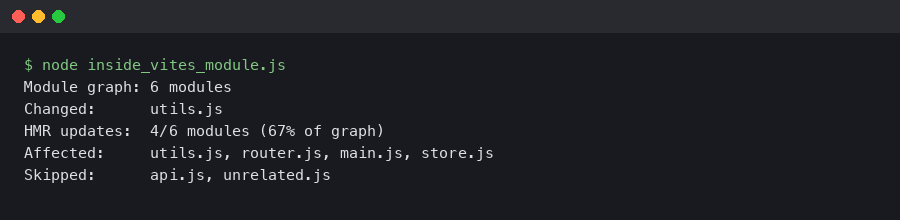
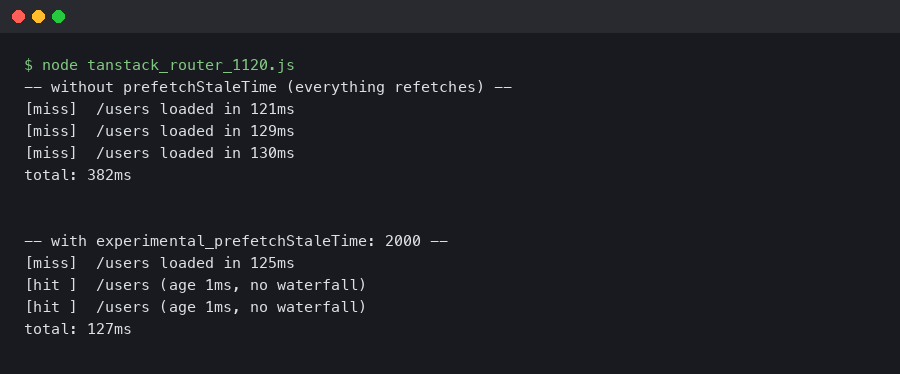
React Query aggressively caches data to minimize network requests. Two key configuration options are staleTime and cacheTime.
staleTime: The duration in milliseconds until cached data is considered stale. While data is fresh (not stale), React Query will return it from the cache without triggering a background re-fetch. Default is0.cacheTime: The duration in milliseconds that inactive query data is kept in the cache. Once a query has no active observers (i.e., no mounted components are using it), it becomes inactive and will be garbage collected aftercacheTime. Default is 5 minutes.
Setting a staleTime of a few minutes for data that doesn’t change often can create an incredibly fast, “instant” browsing experience as users navigate between pages.

Accelerating the Backend with SQL Indexes
A smart caching strategy on the frontend is wasted if the initial data load is slow. As your database tables grow, queries can become slow. The single most effective way to speed up `SELECT` queries is by adding indexes. An index is a special lookup table that the database search engine can use to speed up data retrieval. For our article fetching query, which filters by published_at and orders by created_at, an index can be transformative.
-- Creating a composite index to optimize the article fetching query.
-- This helps the database efficiently find published articles
-- and sort them by creation date without scanning the entire table.
CREATE INDEX idx_articles_published_created
ON articles (published_at, created_at DESC);
-- An index on the foreign key is also crucial for fast joins
-- when fetching articles by a specific author.
CREATE INDEX idx_articles_author_id
ON articles (author_id);This backend optimization directly enhances the user experience, reducing the time spent in the isLoading state of your useQuery hook.
Best Practices and Ecosystem Integration
To get the most out of React Query, it’s essential to follow established best practices and understand how it fits into the broader React ecosystem, which includes a vibrant community discussing everything from Zustand News to testing strategies with React Testing Library News.
Structuring Query Keys
Query keys are the heart of React Query’s cache management. Always use an array for your keys, starting with a general identifier for the data type and followed by any specific parameters. This hierarchical structure makes it easy to invalidate queries granularly or in bulk.
['articles']: Key for the list of all articles.['articles', 10]: Key for a single article with ID 10.['articles', 'search', { query: 'React' }]: Key for a search result.
This allows you to, for example, invalidate all 'articles' queries at once after a major change.
Separating Client and Server State
A common pitfall is trying to manage all application state within React Query. React Query is for server state—data that lives on your server and is fetched asynchronously. For client state—like UI state (e.g., “is a modal open?”), form inputs, or theme settings—it’s better to use React’s built-in state (useState, useReducer) or a dedicated client state manager. The latest Recoil News and Jotai News highlight a trend towards atomic state management, which pairs beautifully with React Query’s domain-specific focus.
Leveraging the Devtools
The React Query Devtools are indispensable for development. They provide a visual interface to inspect the query cache, see the state of each query in real-time, and manually trigger actions like re-fetching or invalidating. They are a must-have for any project using the library, much like Storybook News is central to modern component development.
Conclusion: A Full-Stack Approach to State Management
The latest React Query News underscores a critical evolution in frontend development: effective state management is no longer just a frontend concern. Libraries like TanStack Query provide the tools to build resilient, fast, and responsive user interfaces by declaratively managing server state. However, its true power is unlocked when developers adopt a full-stack mindset, understanding that frontend performance is deeply connected to backend efficiency.
By pairing React Query’s sophisticated caching and state management with well-structured APIs backed by optimized SQL queries, indexes, and transactions, you can build truly world-class applications. Whether you are working in the web with frameworks like Next.js and Remix or building mobile apps in the Expo News ecosystem, this holistic view of data flow—from the database row to the rendered pixel—is the key to mastering modern application development.